Prosocial and Antisocial LifeProTips on Reddit

Natural language processing project delving into the subreddits r/LifeProTips and r/UnethicalLifeProTips.
Read the code on Github here
NLP and API with Reddit
Summary
The LifeProTips subreddit is one of the most popular subreddits in Reddit with over 18.4M members, offering advice, hacks and tips on different aspects of life (family, work, hobbies etc.). It also has multiple offshoots including UnethicalLifeProTips, IllegalLifeProTips and a satire subreddit ShittyLifeProTips.
In this project, we want to investigate the differences between LifeProTips and UnethicalLifeProTips. In their own words, the respective definitions are:
- LPT: Tip that improves your life in one way or another.
- ULPT: Tip that improves your life in a meaningful way, perhaps at the expense of others and/or with questionable legality.
Problem Statement
By building a classification model for the two subreddits, we want to see if we can accurately predict posts for the two subreddits as well as investigate the following:
- We can understand what ‘unethical’ is defined as by society (using the Reddit community as a proxy).
- We can identify if the tips submitted to each subreddit are significantly different in any way, even though both purport to ‘improve lives’.
- As the definition provided by the ULPT subreddit describes anti-social behaviour, we can also seek to understand what constitutes anti-social behaviour.
Project Approach
1. Scraping Reddit
The data was retrieved from our two subreddits r/LifeProTips and r/UnethicalLifeProTips by relying on the requests. As Reddit’s .json format is conveniently structured like a Python dictionary, we are able to easily extract the information from the website, looping through 25 posts at a time.
To give us enough data in our corpus, the loop was called 40 times for each subreddit, although the request resulted in about 990+ posts for each subreddit rather than 1000.
Below is the code used to add each post from LifeProTips into a list. This was duplicated for UnethicalLifeProTips as well.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#Set URL for the subreddit, sorting by new.
lpt_url = 'https://www.reddit.com/r/LifeProTips/new/.json'
#Create empty list and set after to None
lpt_posts = []
after = None
for a in range(40): #Loop 40 times
if after == None and a == 0: #Set URL to current URL for first loop
current_url = lpt_url
elif after == None: #Print message and stop code if after = None due to limit of requests
print('After is null')
break
else: #Set URL to include after value after the first loop
current_url = lpt_url + '?after=' + after
print(current_url)
print(a)
res = requests.get(current_url, headers={'User-agent': 'Alexis 1.0'}) #Request the data from reddit
if res.status_code != 200: #Print error if request fails
print('Status error', res.status_code)
break
current_dict = res.json() #Create dictionary from res.json(
current_posts = [p['data'] for p in current_dict['data']['children']] #Extract posts from dictionary
lpt_posts.extend(current_posts) #Add posts to list
after = current_dict['data']['after'] #Set after value to capture next group of posts
if a > 0: #After the first loop, read the existing csv file into a dataframe and append the new posts to the dataframe
prev_posts = pd.read_csv('lpt_posts.csv')
current_df = pd.DataFrame(current_posts)
new_df = prev_posts.append(current_df)
new_df.to_csv('lpt_posts.csv', index = False)
else: #In the first loop, save the posts as a dataframe in a csv file
pd.DataFrame(lpt_posts).to_csv('lpt_posts.csv', index = False)
#Add a sleep duration to make our requests seem more natural
sleep_duration = random.randint(2,30)
print(sleep_duration)
time.sleep(sleep_duration)
In addition to this, we used the praw library to scrape directly from Reddit, filtering for the top posts in each subreddit (to give us a higher quality of posts to compare). Hence, we have about 1000 posts sorted by new and also 1000 top posts for each subreddit.
2. Text Processing
To process our data for analysis, we removed punctuation, numbers, commonly used words (stopwords) and either lemmatize or stem our words. Since we are interested in the meaning of the words after analysis, we’ll choose to lemmatize them instead as stemming can tend to strip words of their meaning.
There are a few libraries that we could choose from to facilitate our processing. In particular, we considered both the Spacy and Wordnet/NLTK libraries.
Stopwords: The Spacy library stopwords list has more stopwords with 328, compared to the stopwords imported from NLTK, so we decided to go with the Spacy stopwords instead and include “ulpt”,”lpt”,”reddit” as stopwords as well.
Lemmatization: To decide which method to leverage on for lemmatization, we timed the performance of both Spacy and Wordnet in lemmatizing each post. As Wordnet is almost twice as fast (30+ versus 60+ seconds), we have selected the Wordnet lemmatization.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
# Code to clean text
# Function to get the part of speech for a word.
def get_wordnet_pos(word):
"""Map POS tag to first character lemmatize() accepts"""
tag = nltk.pos_tag([word])[0][1][0].upper()
tag_dict = {"J": wordnet.ADJ,
"N": wordnet.NOUN,
"V": wordnet.VERB,
"R": wordnet.ADV}
return tag_dict.get(tag, wordnet.NOUN)
#Function to process a post, remove stopwords and lemmatize
def post_to_words(raw_post):
# Function to convert a raw post to a string of words
# The input is a single string and
# the output is a single string
# 1. Remove HTML.
post_text = BeautifulSoup(raw_post).get_text()
# 2. Remove non-letters.
letters_only = re.sub("[^a-zA-Z]", " ", post_text)
# 3. Convert to lower case, split into individual words.
words = letters_only.lower().split()
# 4. Remove stopwords.
meaningful_words = [w for w in words if w not in stops]
# 5. Lemmatize words
w_lemmatizer = WordNetLemmatizer()
meaningful_words_lemm = [w_lemmatizer.lemmatize(w, get_wordnet_pos(w)) for w in meaningful_words]
# 6. Join the words back into one string separated by space,
# and return the result.
return(" ".join(meaningful_words_lemm))
3. Exploratory Data Analysis
Examples
LifeProTip Example: LPT: If you want a smarter kid, teach your child to read as early as possible and instill in them a love for books. Because as soon as they can read, they can teach themselves. And that will be a life-long advantage over their peers who don’t have that same ability.
UnethicalLifeProTip Example: ULPT: if you’re stuck on an annoying call, put your phone on airplane mode instead of just hanging up. The other person will see “call failed” instead of “call ended”
It definitely looks like the unethical posts are quite unethical, but not necessarily illegal or harmful to others.
EDA
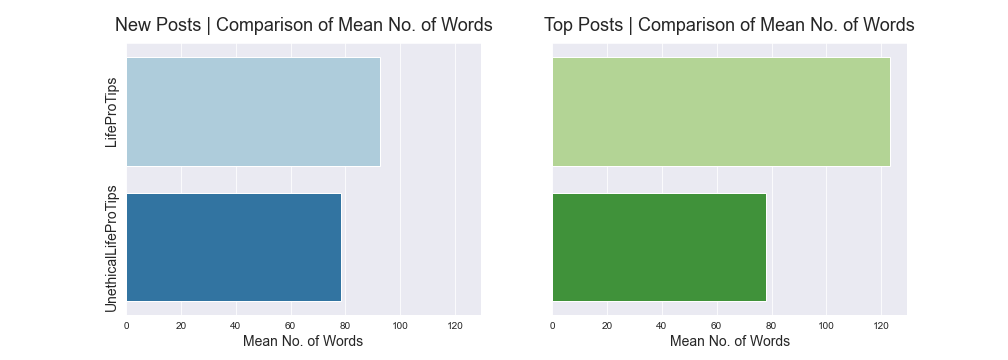
LPT posts tend to have more words than ULPT posts, especially when we look at the top posts which have more than 120 words on average for the title and post body combined.
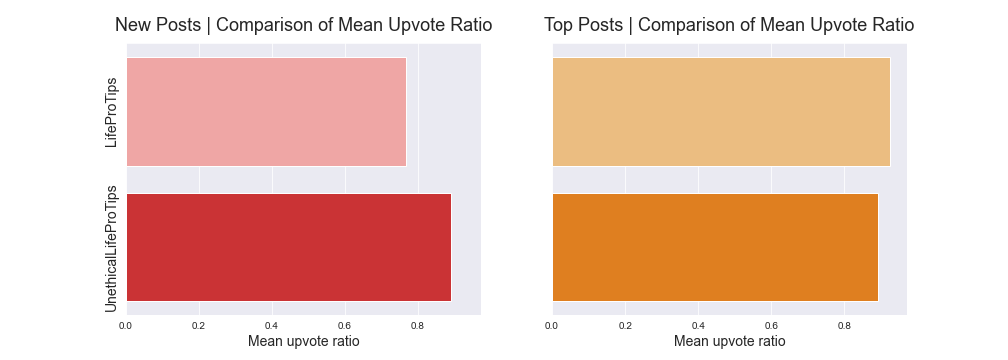
When looking at the upvote ratios, they are comparable between the two subreddits, though we see that LPT new posts tend to have a lower upvote ratio as these posts are more frequent and may have a lower view rate overall.
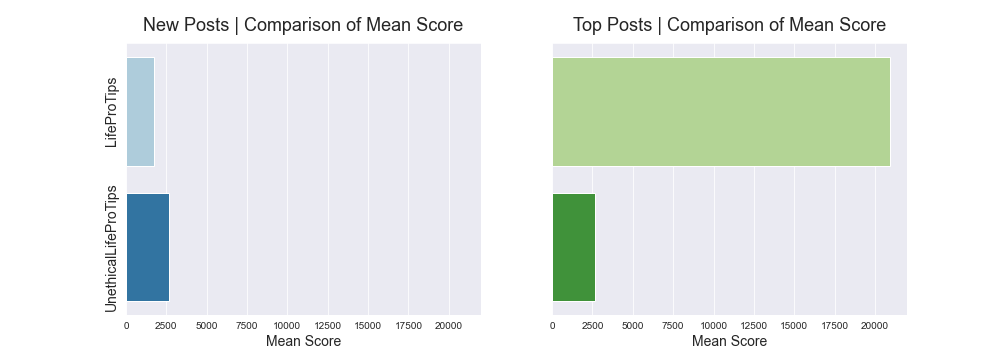
In contrast, when we look at the actual scores for each post, the top LifeProTips posts have far higher means than the ULPT posts. This may be because the community is much larger (18.4m versus 1.1m). A larger community also gives the post more opportunity to reach a wider audience as posts with a lot of upvotes are recommended to people on the main Reddit page.
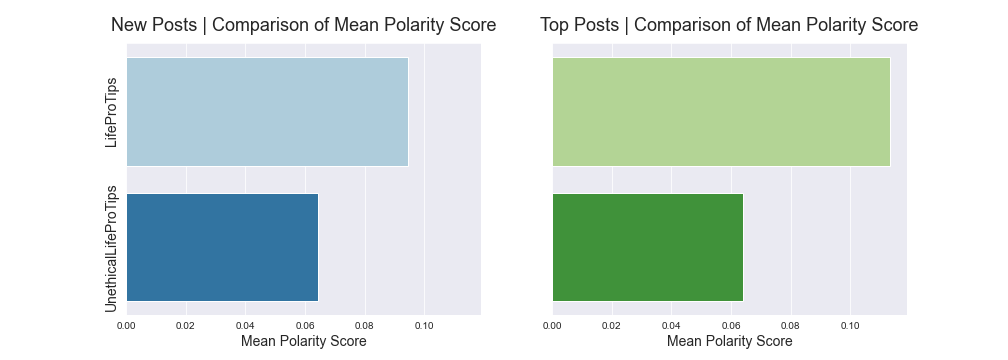
Polarity under TextBlob defines how positive or negative a text is, with -1 being very negative and +1 being very positive. Overall, the LPT posts are slightly more positive.
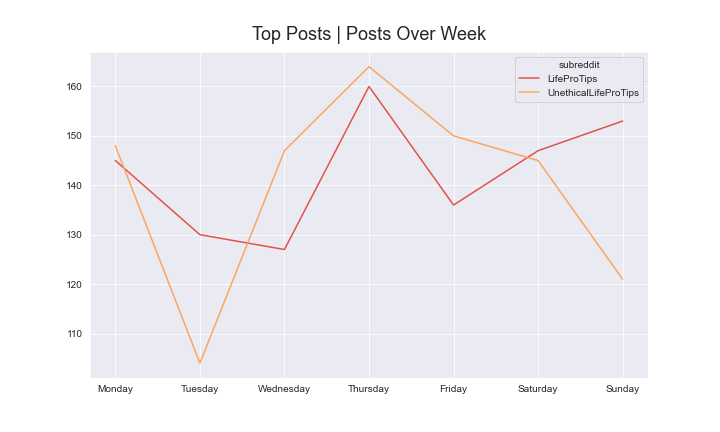
For both subreddits, it looks like the top posts tend to occur more on Thursday, while for LPT posts we also see a peak on Sunday. The posts on Thursday could be benefitimg from the weekend, where people are more likely to have free time and use Reddit, while the peak on Sunday for LPT posts could ostensibly be due to the week about to start and people looking to be productive.

The posts across hours (with time converted to US Eastern Standard Time) show that posts are most frequent late at night and early in the morning.
WordClouds


4. Modeling & Prediction
To create a model for our data, we vectorized vectorizing our posts to create features that would be accepted by the model functions. Both the Count Vectorizer or TF-IDF (term frequency–inverse document frequency) Vectorizer, both of which have hyperparameters we can tune (e.g. maximum features), were tested.
We also leveraged on GridSearchCV to find the best combination of hyperparameters.
The top-performing model was the MultinomialNB algorithm that used the TF-IDF vectorizer. We further tuned this by looking at the top words in the misclassified posts. This led us to add in new stopwords such as ‘home’, ‘engine’, ‘fuel’, ‘place’, ‘dry’, ‘people’,’try’,’work’, ‘like’.
After further tuning, we turned to the features that overlapped the least for our two classes to look at what could be differentiating the classes:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
******************
Features for ULPT
******************
reply
free trial
usps
busy
card
care
payment
personal information
resume
new account
moment
lock
******************
Features for LPT
******************
help
know
thin
dealership
edit
feel guilty
gotten
good way
perform
wife
vehicle
thing people
What seemed to differentiate the unethical posts?
Free trial and new account seem to refer to getting away with not paying for a service. The features seem to imply that the ULPT tends to be more self-centered (which we would expect). For some reason, tips about the USPS seem to feature prominently. In comparison, when we look at the predictive features for LPT posts, it is interesting to note:
There seem to be many post edits where the author comes back to add to their post. (Since we are looking at top posts, they might be thanking the community for the upvotes and awards.) “help” and “know” are top predictors, showcasing that the subreddit is more helpful. ‘Feel guilty’ seems to indicate that the people posting LPTs are nicer Ultimately, it is hard to definitively say that any one feature is very important, over the others, as our model is based on the interaction of many, many features.
Conclusion & Recommendations
Based on our investigations and model, while we managed to create a model that successfully predicts around 80% of all posts. Some things we can conclude are:
-
Unethical == materialism?: There seems to be a greater focus on purchases and ‘gaming’ the system, in our ULPT posts, suggesting that people see this behaviour as unethical (but still beneficial to yourself.) Aside from this theme, we can’t see any strong indications for the term.
-
Defining unethical: While there are some themes that stand out for both subreddits, we can’t explicitly conclude what ‘unethical’ or anti-social behaviour is. However, this may come down to the fact that since these posts are written from a 1st person POV and focused on actions, we may not see language that defines negative behaviour. We may be better off examining a different subreddit e.g. AmITheAsshole.
-
What are ‘tips’? We can definitely conclude that the tips submitted to both are quite similar and overlap in language and themes. Many of the tips submitted have to do with wanting to know things, purchases, work, and time.
Read the full code on Github here